

In the rapidly evolving world of machine learning, Python has emerged as one of the most popular languages data scientists and developers use. Python’s rich ecosystem of libraries provides a vast array of tools to make machine learning development faster, easier, and more efficient. With the continuous evolution of these libraries, it is essential to stay up-to-date with the latest trends and developments to maintain a competitive edge. In this blog post, we will explore the top 6 most popular Python libraries for machine learning in 2023 and how they impact the development of machine learning applications. We will cover each library’s essential features, functionalities, and use cases. Whether you are a seasoned machine learning practitioner or a beginner, this article will provide valuable insights into the tools driving innovation in machine learning.
What is Machine Learning?
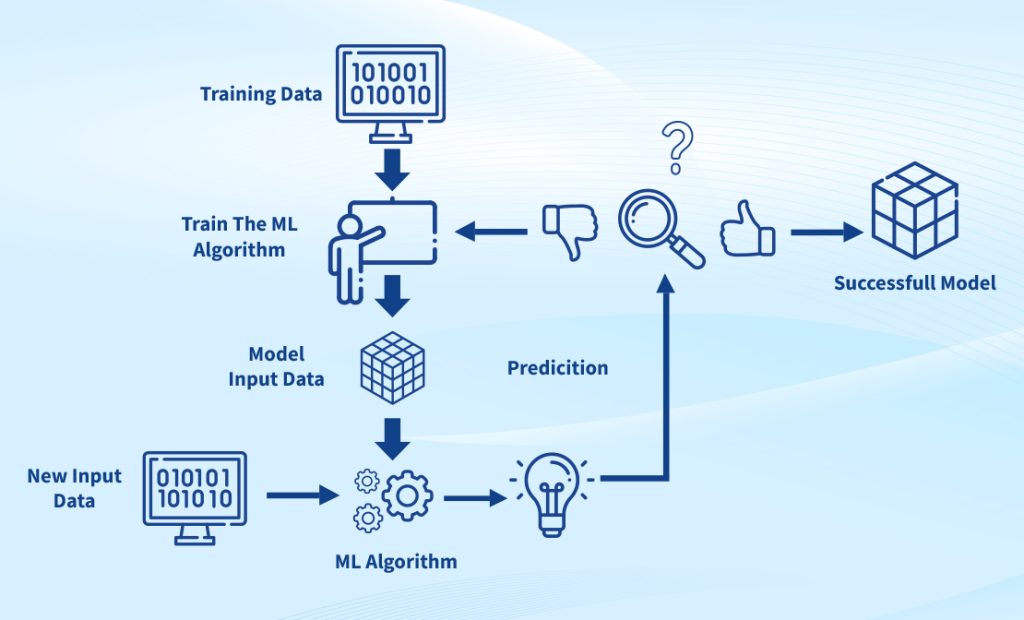
Machine learning is a subset of artificial intelligence (AI) that involves training computer systems to learn and improve their performance over time based on analyzing large volumes of data. It involves using mathematical algorithms and statistical models to analyze data, identify patterns, and make predictions or decisions without being explicitly programmed.
Machine learning enables computers to learn from experience and improve their performance without human intervention. This can be achieved through various techniques, such as supervised, unsupervised, semi-supervised, and reinforcement learning.
Machine learning has many applications, including natural language processing, computer vision, speech recognition, fraud detection, recommendation systems, etc. As more data becomes available and computing power increases, the potential for machine learning to transform various industries and sectors is only growing.
The 6 Most Popular Python Libraries for Machine Learning
Python has emerged as a popular language for machine learning due to its simplicity, flexibility, and rich ecosystem of libraries and tools. The following are the most popular Python libraries for machine learning:
TensorFlow
TensorFlow is an open-source library developed by Google for building and training machine learning models. It is one of the most widely used libraries for deep learning, natural language processing (NLP), and computer vision applications. TensorFlow is written in C++ but has APIs for several programming languages, including Python.

Use Cases:
Computer Vision: TensorFlow is commonly used in computer vision applications, such as object detection, image recognition, and face recognition.
Natural Language Processing: TensorFlow can be used for natural languages processing tasks, such as text classification, sentiment analysis, and machine translation.
Speech Recognition: TensorFlow can build and train speech recognition and synthesis models.
Pros:
Flexible Architecture: TensorFlow provides a flexible architecture for building and training various machine learning models, from simple linear regression to complex deep learning models.
Scalability: TensorFlow supports distributed computing, allowing it to scale to large datasets and complex models.
Popularity: TensorFlow is one of the most widely used machine learning libraries and has a large community of developers contributing to its development and support.
Integration: TensorFlow integrates well with other Python libraries, such as Keras and Pandas, which can simplify the development of machine learning workflows.
Cons:
Steep Learning Curve: TensorFlow has a steep learning curve, especially for beginners who need to become more familiar with machine learning concepts or programming in Python.
Complexity: TensorFlow’s flexibility can also be a disadvantage, making it more challenging to build and train models, especially for smaller datasets or more straightforward applications.
Debugging: Debugging TensorFlow models can be challenging, as errors may occur due to issues with the model architecture, the input data, or the optimization algorithm.
Performance: While TensorFlow is known for its scalability, some applications may have better choices. It may be slower than other libraries for specific tasks or model architectures.
PyTorch
PyTorch is an open-source machine-learning library developed by Facebook. It is primarily used for deep learning applications, including computer vision and natural language processing (NLP). PyTorch is written in Python and is known for its dynamic computational graph, allowing more flexibility in building and training deep learning models.
Use Cases:
Computer Vision: PyTorch is commonly used in computer vision applications, such as object detection, image recognition, and segmentation.
Language Processing: PyTorch is also used for natural language processing tasks, such as text classification, sentiment analysis, and machine translation.
Scientific Computing: PyTorch supports numerical computing and can be used for scientific applications, such as physics simulations and signal processing.
Pros:
Flexibility: PyTorch’s dynamic computational graph provides more flexibility in building and training deep learning models, making it easier to experiment with different architectures and optimize performance.
Third-Party Integration: PyTorch integrates well with other Python libraries, such as Numpy and Pandas, which can simplify the development of machine learning workflows.
Ease of Use: PyTorch has a relatively simple API that is easy to use, especially for developers already familiar with Python and machine learning concepts.
Community: PyTorch has a growing community of developers contributing to its development and support and a large ecosystem of third-party libraries and tools.
Cons:
Limited Scalability: While PyTorch supports distributed computing, it may not be as scalable as TensorFlow for large datasets or complex models.
Lack of Standardization: PyTorch needs a standard API or architecture for building and training models, making it harder to share or reproduce models across different environments.
Documentation: PyTorch’s documentation can be less comprehensive or less organized than other libraries, which may make it more challenging for developers to learn or use effectively.
Efficiency: PyTorch is generally fast and efficient; some applications may have better choices, especially those requiring high-performance computing or specialized hardware.
Scikit-learn:
Scikit-learn, or sklearn, is a popular open-source machine-learning library for Python. It provides various data analysis, modelling, and evaluation tools and is widely used in industry and academia.

Use Cases:
Classification: Scikit-learn provides several classification algorithms for solving classification problems. These algorithms include logistic regression, decision trees, random forests, naive Bayes, and support vector machines (SVM).
Regression: Scikit-learn also provides several regression algorithms for solving regression problems. These algorithms include linear regression, ridge regression, lasso regression, and elastic net regression.
Clustering: Scikit-learn provides several clustering algorithms for grouping similar data points. These algorithms include K-means clustering, hierarchical clustering, and spectral clustering.
Dimensionality Reduction: Scikit-learn provides several algorithms for reducing the dimensionality of the dataset. These algorithms include Principal Component Analysis (PCA), Non-negative Matrix Factorization (NMF), and t-SNE.
Model Selection: Scikit-learn provides several tools for model selection and assessment, including cross-validation, grid search, and performance metrics such as accuracy, precision, recall, and F1 score.
Preprocessing: Scikit-learn provides several valuable tools for cleaning and transforming data before applying machine learning algorithms. These tools include feature scaling, feature selection, and data normalization.
Text analysis: Scikit-learn provides several tools for text analysis, including text preprocessing, feature extraction, and classification algorithms for text classification and sentiment analysis.
Pros:
Comprehensive: Scikit-learn provides a comprehensive set of tools for machine learning, including many popular algorithms and techniques.
Easy to Use: Scikit-learn has a simple and consistent API, making it easy to learn and use for both novice and experienced developers.
Library Integration: Scikit-learn integrates well with other Python libraries, such as Pandas and Numpy, which can simplify the development of machine learning workflows.
Parallel Processing: Scikit-learn is optimized for performance and provides support for parallel processing, which can improve the speed of model training and evaluation.
Cons:
Limited Scalability: Scikit-learn may not be as scalable as other libraries, such as TensorFlow or PyTorch, for large datasets or complex models.
Lack of Flexibility: Scikit-learn provides a limited set of tools for deep learning and may not be as flexible as other libraries for building and training custom models.
Limited Support for GPU: Scikit-learn provides limited support for GPU computing, which can limit its performance on some tasks.
Lack of Advanced Features: Scikit-learn may not provide some advanced features or techniques other libraries provide, such as transfer learning or generative adversarial networks.
Related Article: Why Python and Django Are a Top Choice for Web Development
Keras
Keras is an open-source deep-learning library for Python. It is built on TensorFlow and provides a user-friendly API for building and training deep learning models.

Use Cases:
Image classification: Keras provides several pre-trained models and tools for image classification tasks. These models include VGG16, ResNet, and InceptionNet, which can be used for object recognition and face detection.
Recommendation systems: Keras can be used to build recommendation systems that suggest products or content to users based on their preferences. These systems typically use techniques such as collaborative filtering and matrix factorization.
Generative models: Keras provides tools for building and training generative models such as generative adversarial networks (GANs) and variational autoencoders (VAEs). These models can be used for image and text generation tasks.
Transfer learning: Keras provides tools for using pre-trained models and fine-tuning them for specific tasks. This is useful for scenarios with limited data for training a model.
Pros:
User-Friendly: Keras provides a simple and intuitive API for building and training deep learning models, making it easy for novice and experienced developers to use.
Flexibility: Keras supports a wide range of deep learning models, including convolutional neural networks (CNNs), recurrent neural networks (RNNs), and transformers.
Improve Performance: Keras provides support for GPU computing, which can significantly improve the speed of model training and evaluation.
Cons:
Limited Control: Keras may provide less control over the details of the deep learning model than other libraries, such as TensorFlow or PyTorch. Limited Scalability: Keras may not be as scalable as other libraries for large datasets or complex models.
Lack of Advanced Features: Keras may need to provide advanced features or techniques other libraries provide, such as generative adversarial networks or attention mechanisms.
Lack of Compatibility: Keras may need to be fully compatible with some of the newer features of TensorFlow.
Pandas:
Pandas is an open-source data analysis and manipulation library for Python. It provides easy-to-use data structures and data analysis tools for handling and processing structured data.

Use Cases:
Data preparation: Pandas are used for data preparation in machine learning, including data cleaning, handling missing values, and data normalization. Pandas provide a rich set of functions for data manipulation, such as filtering, grouping, and pivoting.
Data exploration: Pandas are used for data exploration and visualization in machine learning. It provides a range of tools for data visualization, including scatter plots, histograms, and heat maps. These visualizations can help identify data trends, correlations, and patterns.
Feature engineering: Feature engineering involves creating new features from existing ones to improve the accuracy of machine learning models. Pandas provide several tools for feature engineering, such as creating new columns from existing ones, scaling and transforming features, and encoding categorical variables.
Data merging and joining: In machine learning, it is common to have data in multiple tables that need to be combined. Pandas provide functions for merging and joining datasets based on standard columns.
Time series analysis: Pandas provides specialized tools for working with time series data, such as resampling, rolling windows, and lagging. These tools are helpful for time series forecasting and anomaly detection.
Data serialization: Pandas provides functions for reading and writing data in different formats, including CSV, Excel, SQL, and JSON. This makes loading data from other sources easy and exporting results to various formats.
Pros:
Easy-to-Use: Pandas provides a simple and intuitive API for working with structured data, making it easy for novice and experienced developers to use.
Wide range of data types: Pandas supports a wide range of data types and manipulation operations, making it a versatile tool for data analysis and preprocessing.
Simplify development: Pandas integrates well with other Python libraries, such as Scikit-learn and Matplotlib, which can simplify the development of machine-learning workflows.
Cons:
Limited Scalability: Pandas may not be as scalable as other libraries for large datasets or complex data manipulation tasks.
Memory Consumption: Pandas can be memory-intensive, especially for large datasets, which can limit their performance on some tasks.
Lack of Flexibility: Pandas may provide less flexibility than other libraries with unstructured or non-tabular data.
NumPy:
NumPy is an open-source library for the Python programming language. It supports large, multi-dimensional arrays and matrices and a wide range of mathematical operations for working with them.

Use Cases:
Data Processing: NumPy is often used to preprocess and transform data for machine learning, as it provides efficient and flexible tools for handling large datasets.
Linear Algebra: NumPy provides a range of linear algebra operations, such as matrix multiplication and eigenvalue calculation, which are essential for many machine learning models.
Signal Processing: NumPy provides tools for signal processing, such as Fourier transforms and signal-to-filter, which help work with audio and image data.
Scientific Computing: NumPy provides a range of scientific computing functions, such as interpolation and optimization, which are helpful for many machine learning applications.
Pros:
Efficiency: NumPy is designed to be highly efficient, with optimized C code under the hood, which makes it ideal for working with large datasets.
Versatility: NumPy provides a wide range of tools for working with arrays and matrices and a wide range of mathematical operations, making it a versatile library for many machine-learning tasks.
Integration: NumPy integrates well with many other Python libraries, such as Pandas and Scikit-learn, which can simplify the development of machine learning workflows.
Community Support: NumPy has a large and active community, which provides a wealth of resources and support for users.
Cons:
Steep Learning Curve: NumPy can have a steep learning curve for users who need to become more familiar with the mathematical concepts underlying it.
Lack of Flexibility: NumPy is designed primarily for working with arrays and matrices, which can limit its flexibility for some machine learning tasks.
Limited Support for Parallel Computing: NumPy may not provide as much support for parallel computing as other libraries, which can limit its performance on some tasks.
Memory Consumption: NumPy can be memory-intensive, especially for large arrays or matrices, limiting its performance on some systems.
How to Choose the Right Python Library for Your ML Project?
Choosing the proper Python library for your machine learning project can be a critical decision that can impact the success of your project. Here are some factors to consider when selecting a Python library for your ML project:
Project Requirements:
The first step is to consider your project’s specific requirements, which will help you identify the libraries that meet your needs.
Community Support:
It is essential to consider the size and activity of the community around a Python library. A library with an active community can provide resources and support to help you overcome obstacles and solve problems.
Ease of Use:
Look for a library that is easy to learn and use, especially if you are new to machine learning or Python. Libraries with good documentation, user-friendly APIs, and a shallow learning curve can help you get up to speed quickly.
Flexibility:
Consider the flexibility of the library you choose. A library that provides a wide range of tools and functionality can be helpful in a variety of projects and can help you adapt to changing requirements.
Integration:
Consider how well the library integrates with other Python libraries and tools you might be using. A library that integrates well with other tools can simplify the development process and make building, testing, and deploying your models easier.
Performance:
Consider the performance of the library for your particular use case. Some libraries may be better suited for handling large datasets or specific models.
Licensing:
It is essential to consider the licensing terms of a library, especially if you are building a commercial application or working in a regulated industry.
By considering these factors, you can select a Python library that meets the requirements of your ML project and helps you build high-quality models efficiently and effectively.
Related Article: A Detailed Guide to Find the Best Web App Development Partner for Your Startup?
How can AddWeb Solution help you with your Machine Learning project?
As a leading Python development company, we help you build a successful machine-learning project by providing expert Python developers with experience developing and deploying machine-learning models. Here are some ways a Python development company can help:
Domain Expertise:
With machine learning experience, we provide domain expertise that can help you better understand your problem space and data. They can work with you to design and implement data pipelines, feature engineering, model selection, and evaluation.
Customized Solutions:
We have a team of expert python developers who help you build customized solutions tailored to your needs. They can help you identify the best tools and technologies for your project and provide you with the right team to do the job.
Scalability:
We help you build scalable solutions for large datasets and complex models. With us, you leverage cloud technologies and distributed computing to process your data and run your models at scale.
Performance Optimization:
As a Python development agency, we can help you optimize the performance of your machine-learning models by leveraging advanced techniques such as parallel processing, vectorization, and memory optimization.
Quality Assurance:
We have an experienced quality analyst who can help you ensure the quality of your machine learning models by providing robust testing and validation processes that help to identify and fix errors and improve performance.
Deployment and Maintenance:
Our DevOps engineers help you to maintain your machine learning models by providing continuous monitoring and support, ensuring that your models perform optimally and deliver value to your business.
A leading Python development company, we help you build successful machine learning projects by providing expert Python developers with domain expertise, customized solutions, scalability, performance optimization, quality assurance, deployment, and maintenance to help you succeed.
Conclusion
In conclusion, data science projects can be complex and challenging, and selecting the right tools and resources is critical to success. Python libraries have become essential tools for machine learning projects, providing many functionalities to build high-quality models. However, choosing a suitable library for your project requires careful consideration of several factors, including project requirements, community support, ease of use, flexibility, integration, performance, and licensing.
Selecting a suitable Python library is just one piece of the puzzle. Building successful data science projects requires a comprehensive understanding of the problem, data, and models and advanced programming and statistical skills. By combining the right tools with expertise, data scientists can create data-driven solutions to help businesses and organizations make better decisions and drive innovation.
Frequently Asked Questions
The top 6 Python libraries for machine learning are TensorFlow, PyTorch, scikit-learn, Keras, Pandas, and NumPy. These libraries are widely used for various aspects of machine learning development.
TensorFlow is an open-source machine learning framework developed by Google. It is known for its flexibility and scalability, making it suitable for building and training complex deep learning models.
PyTorch is another popular machine learning library that excels in dynamic computation graphs. It is often favored for its simplicity and is known for its ease of use, especially in research and experimentation.
Scikit-learn is a versatile library for classical machine learning algorithms. It provides simple and efficient tools for data analysis and modeling and is widely used for tasks like classification, regression, and clustering.
Keras is an open-source deep learning API that acts as a high-level interface for TensorFlow. It simplifies the process of building and training deep learning models, making it accessible for developers of all skill levels.
Pandas is a powerful data manipulation library. It simplifies data preparation and analysis, making it easier to clean, preprocess, and transform data before feeding it into machine learning models.
NumPy is a fundamental library for scientific computing in Python. It provides support for large, multi-dimensional arrays and matrices, essential for mathematical operations and numerical computing in machine learning.